


ViTok Paper Explained
[Daily Paper Review: 18-01-25] Learnings from Scaling Visual Tokenizers for Reconstruction and Generation

Modern image and video generation models rely on two key components: a visual tokenizer and a generator. The visual tokenizer compresses raw pixels into a lower-dimensional latent space, which the generator then uses to create new images or videos. While significant progress has been made in scaling Transformer-based generators, the visual tokenizer component has largely been overlooked. Most tokenizers are based on convolutional neural networks (CNNs), which have not been scaled or optimized to the same extent as generators. This raises several open questions:
How do design choices in auto-encoders (used for tokenization) affect reconstruction and downstream generative performance?
Does scaling the tokenizer (auto-encoder) improve its ability to compress and reconstruct images/videos, and does this translate to better generative performance?
What is the role of the encoder, decoder, and bottleneck size in the auto-encoder, and how do they impact reconstruction and generation?
These questions are critical because the tokenizer is the first step in the generative pipeline, and its performance directly influences the quality of the latent representations that the generator works with.
ViTok (Vision Transformer Tokenizer) is a novel auto-encoder architecture designed to address the limitations of traditional CNN-based tokenizers. It replaces the convolutional backbone with a Vision Transformer (ViT) enhanced with Llama (a large-scale language model architecture), making it more scalable and efficient for visual tokenization. ViTok is specifically designed to explore the effects of scaling auto-encoders for both reconstruction and generation tasks.
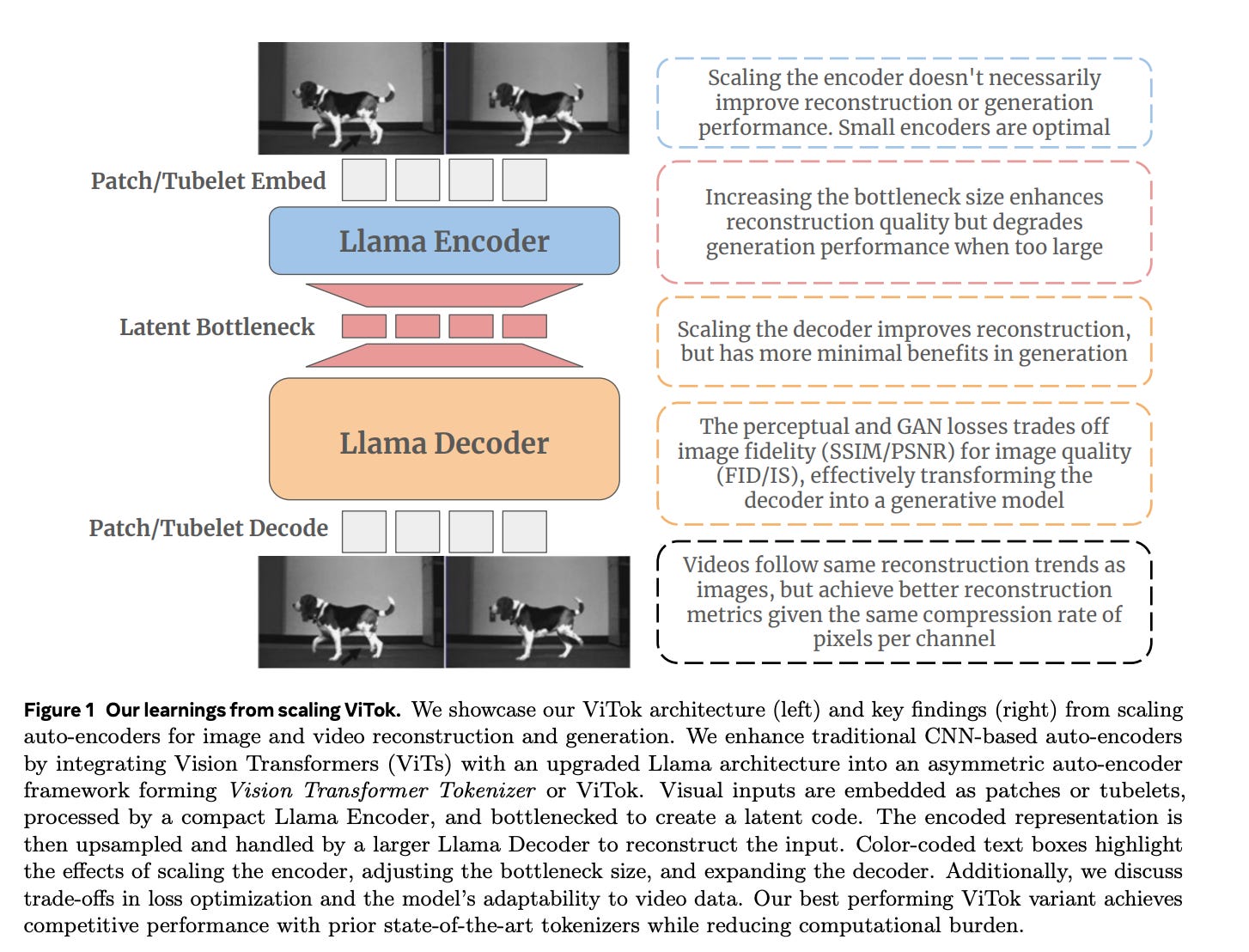
Key Findings from ViTok
Bottleneck Size:
Increasing the bottleneck size improves reconstruction but can degrade generative performance when too large.
Encoder Scaling:
Scaling the encoder provides minimal gains for reconstruction or generation. Lightweight encoders are optimal.
Decoder Scaling:
Scaling the decoder improves reconstruction quality but has mixed effects on generative performance. The decoder acts partly as a generator, filling in local textures.
Loss Trade-Offs:
Using perceptual and GAN losses trades off image fidelity (SSIM/PSNR) for image quality (FID/IS), effectively transforming the decoder into a generative model.
Video Reconstruction:
Videos follow the same reconstruction trends as images but achieve better reconstruction metrics at the same compression rate due to temporal redundancy.
Deep Dive into Continuous Visual Tokenization and ViTok
This section provides a detailed explanation of the continuous visual tokenization framework and the ViTok (Vision Transformer Tokenizer) architecture. We will break down the mathematical formulations, the steps involved, and the key design choices.
Continuous Visual Tokenization
Variational Auto-Encoder (VAE) Framework
The Variational Auto-Encoder (VAE) is a probabilistic framework used to learn a compressed latent representation of visual inputs (images or videos). It consists of two main components:


Scalable Auto-Encoding Framework (ViTok)
ViTok replaces the traditional CNN-based encoder and decoder with a Vision Transformer (ViT) architecture, enabling better scalability and performance.




Architecture
Encoder and Decoder: Based on Vision Transformer (ViT) with modifications from Llama:
SwiGLU Activation: Improves performance and scalability.
3D Axial RoPE: Captures spatiotemporal relationships effectively.
Training Scale: Designed to scale without being constrained by data size.
Datasets
Images:
Training: Shutterstock (450M images) and ImageNet-1K (1.3M images).
Evaluation: ImageNet-1K validation set and COCO-2017 validation set.
Videos:
Training: Shutterstock video dataset (30M videos, each with over 200 frames at 24 fps).
Evaluation: UCF-101 and Kinetics-700.
E as the Main Bottleneck in Image Reconstruction
This section investigates the role of E (the total dimensionality of the latent space, defined as E=L×C as the primary bottleneck in image reconstruction performance for ViTok. The experiments explore how E influences reconstruction quality across different configurations, patch sizes, and resolutions. Here’s a detailed breakdown:


The Impact of EE in Image Generation
This section explores how the total dimensionality of the latent space (E=L×C) influences generative performance in downstream tasks. Unlike reconstruction, where EE has a strong linear correlation with performance, generative tasks exhibit a more complex relationship with EE. Here’s a detailed breakdown of the experiments, findings, and key insights:

Scaling Trends in Auto-Encoding
This section investigates how scaling the encoder and decoder in ViTok impacts reconstruction and generation performance. The experiments focus on understanding the effects of scaling these components independently while keeping other parameters fixed. Here’s a detailed breakdown of the experiments, findings, and key insights:

A Trade-Off in Decoding
This section explores the trade-offs in the decoder's role between reconstruction fidelity (SSIM/PSNR) and generative quality (FID/IS). The experiments investigate how different loss functions and training strategies influence the decoder's behavior, shifting it from a strict reconstruction model to a more generative model. Here’s a detailed breakdown of the experiments, findings, and key insights:

Video Results
This section extends the application of ViTok to video tasks, focusing on the impact of EE (total latent dimensionality) on video reconstruction and the inherent compressibility of video data. The experiments explore how spatial and temporal compression affect reconstruction performance and how video length influences compressibility. Here’s a detailed breakdown of the experiments, findings, and key insights:


Key Insights
Image Reconstruction:
ViTok achieves SOTA rFID scores with fewer FLOPs compared to CNN-based tokenizers.
Scaling the decoder to Large further improves reconstruction metrics.
Image Generation:
ViTok maintains competitive performance in class-conditional image generation at both 256p and 512p resolutions.
Video Reconstruction:
ViTok achieves SOTA rFVD scores and demonstrates efficiency in video reconstruction.
Matches the performance of LARP with fewer tokens and FLOPs.
Video Generation:
ViTok achieves SOTA gFVD scores at 1024 tokens and remains competitive at 512 tokens.
Demonstrates efficiency and scalability in video generation tasks.
Conclusion
ViTok demonstrates state-of-the-art performance in both image and video reconstruction and generation tasks while significantly reducing computational FLOPs. Its efficiency and versatility make it a strong contender for scalable visual tokenization in generative model