


VideoRAG Paper Explained
[Daily Paper Review: 13-01-25] VideoRAG: Retrieval-Augmented Generation over Video Corpus

In the world of artificial intelligence, Retrieval-Augmented Generation (RAG) has emerged as a game-changer, enabling AI systems to generate accurate and contextually rich responses by grounding their outputs in external knowledge. However, traditional RAG systems have largely relied on textual information, with only recent advancements beginning to explore images. But what about videos?
Problem:
The primary issue addressed in the paper is the limitation of existing Retrieval-Augmented Generation (RAG) systems in generating factually accurate and contextually rich responses. While RAG systems have been successful in incorporating external knowledge, they have largely focused on textual information, with only recent advancements considering images. However, these systems largely overlook videos, which are a rich source of multimodal knowledge. Videos can represent events, processes, and contextual details more effectively than text or static images due to their temporal dynamics, spatial details, and multimodal cues (e.g., visual, auditory, and textual information).
Existing approaches that do consider videos have two major limitations:
Predefined Video Retrieval: Some systems assume that the relevant video is already known and only focus on extracting relevant frames from that video. This approach is not scalable for general-use cases where the system needs to dynamically retrieve relevant videos based on user queries.
Text-Only Conversion: Other systems convert videos into textual descriptions (e.g., subtitles or captions) and use these textual representations in text-based RAG pipelines. This approach discards the multimodal richness of videos, such as visual cues and temporal dynamics, which are often essential for answering complex queries.
For example, in a query like "How does the expression of the dog change when it is angry?", textual descriptions might mention barking or growling but fail to capture visual cues like baring teeth or raised hackles, which are critical for accurately interpreting the dog's emotional state.
Solution: VideoRAG
The authors propose VideoRAG, a novel framework that addresses these limitations by:
Dynamic Video Retrieval: VideoRAG dynamically retrieves relevant videos from a large video corpus based on their relevance to the query, rather than assuming the video is predefined.
Multimodal Utilization: VideoRAG leverages both visual and textual information from videos during the response generation process, preserving the multimodal richness of video content.
Integration with Large Video Language Models (LVLMs): VideoRAG utilizes Large Video Language Models (LVLMs), which can directly process video content (both visual and textual information) in a unified framework. This allows the system to effectively capture the temporal dynamics, spatial details, and multimodal cues present in videos.
Additionally, to handle cases where textual descriptions (e.g., subtitles) are not available, VideoRAG employs automatic speech recognition (ASR) techniques to generate textual transcripts from videos. This ensures that both visual and textual modalities are utilized even when explicit textual annotations are absent.



Detailed Explanation of VideoRAG Method
VideoRAG extends the traditional Retrieval-Augmented Generation (RAG) framework by incorporating video content as an external knowledge source. The method consists of three key steps: Video Retrieval, Video-Augmented Response Generation, and Auxiliary Text Generation (for videos without subtitles). Below is a detailed breakdown of each step



Results
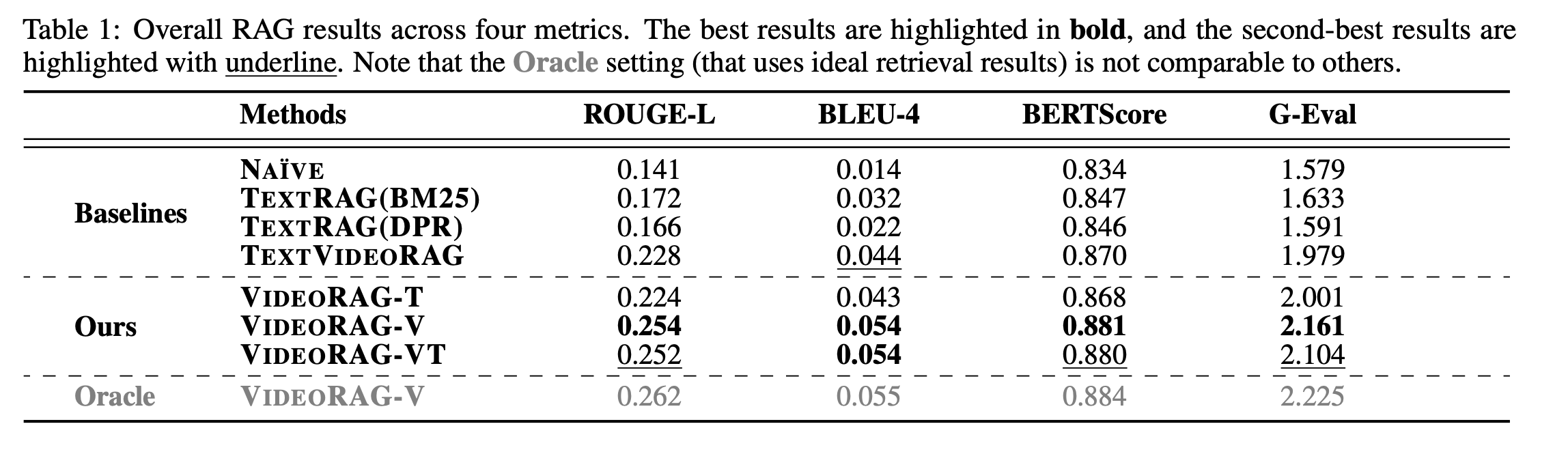
VideoRAG Variants:
VIDEORAG-V (visual-only) and VIDEORAG-VT (visual + textual) achieve the highest performance across all metrics (ROUGE-L, BLEU-4, BERTScore, G-Eval), significantly outperforming text-based RAG baselines like TEXTRAG (BM25/DPR) and TEXTVIDEORAG.
VIDEORAG-V slightly outperforms VIDEORAG-VT, suggesting that visual features alone often encapsulate sufficient information for answer generation.
Oracle Performance: The oracle version of VideoRAG (using ground-truth videos) achieves the best results, indicating room for improvement in video retrieval mechanisms.
Textual vs. Visual: Even VIDEORAG-T (text-only, using video transcripts) outperforms TEXTRAG, showing that video-derived textual content is more useful than general encyclopedic text (e.g., Wikipedia) for RAG.
Performance Insights:
VideoRAG variants outperform baseline models, confirming that videos provide richer and more detailed information than text-based sources alone.
Visual features play a critical role in performance, often encapsulating key information conveyed through textual descriptions.
Impact of Retrieval Quality:
Query-relevant video retrieval significantly enhances answer quality compared to random video selection.
The Oracle setting (ideal video retrieval) achieves the highest performance, emphasizing the potential for improving video retrieval methods.
Textual vs. Visual Features:
Textual features have stronger semantic alignment with text-based queries, leading to better retrieval performance.
Combining textual and visual features achieves the best results, showcasing their complementary nature.
Optimal Feature Combination:
Balancing textual and visual features with a slight emphasis on textual features (optimal ratio: 0.5–0.7) maximizes retrieval performance.
Category-Specific Performance:
VideoRAG demonstrates robust performance across diverse query types.
Visual content particularly enhances answers in categories requiring detailed visual information, such as cooking and preparation methods.
Ablation Studies:
Incorporating videos significantly improves performance over text-only baselines.
Combining videos with encyclopedic text sources slightly degrades performance, likely due to redundancy or conflicting details from text.