VAR Paper Explained
[Daily Paper Review: 01-01-25] Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction

Introduction
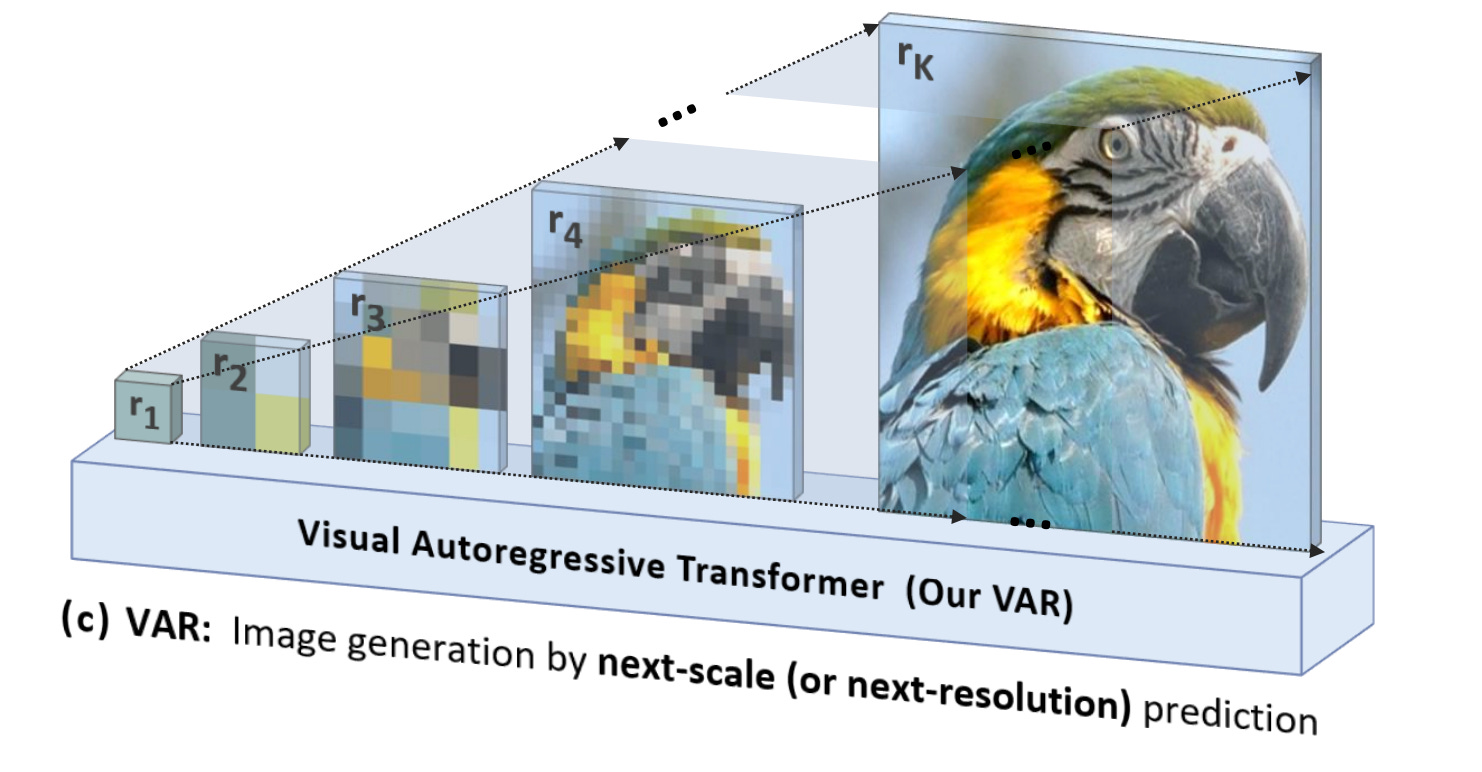
Autoregressive (AR) models are a cornerstone of generative modeling, excelling in sequential domains like natural language processing, where predicting the next token based on previous tokens aligns naturally with linguistic structure. However, in image generation, AR modeling faces challenges due to the lack of inherent order in image pixels. Human visual perception involves grasping large-scale features first, followed by fine-grained details—an intuition that Visual Autoregressive Modeling (VAR) leverages effectively. Unlike traditional AR models, VAR predicts the next scale of an image rather than the next token, overcoming structural and computational limitations.
Challenges in Traditional Autoregressive Image Modeling
1. Unidirectional Dependency
In AR models, quantized tokens derived from images are processed sequentially.
This enforces a strict unidirectional dependency, introducing structural degradation and limiting expressiveness.
2. Lack of Bidirectional Generalization
AR models struggle with tasks requiring bidirectional reasoning, such as predicting the top of an image given its bottom or completing arbitrary regions.
3. High Computational Complexity
Traditional AR image modeling has a computational complexity of O(n^6), where n is the resolution of the image tokens. This exponential cost makes scaling AR models impractical for high-resolution images.
VAR: Next-Scale Prediction
Key Innovation
VAR replaces unidirectional next-token prediction with next-scale prediction, processing tokens hierarchically across scales. This mimics human visual perception, where large-scale features are addressed first, followed by finer details.
Computational Complexity: AR vs. VAR
AR
Quantized Tokens:
After applying a VQ-VAE (Vector Quantized Variational Autoencoder) or similar encoder, the image is converted into a grid of quantized tokens of size h×w where h=w=n
Total number of tokens: T=n^2
Self-Attention Complexity:
In AR, the i-th token attends to all previous tokens. This quadratic self-attention results in a time complexity of:
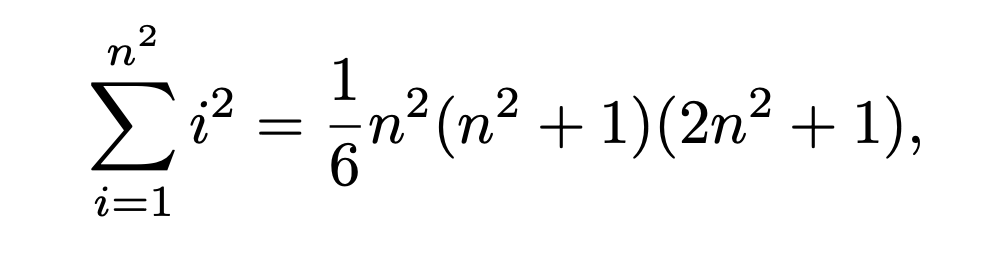
Equivalent to O(n^6)
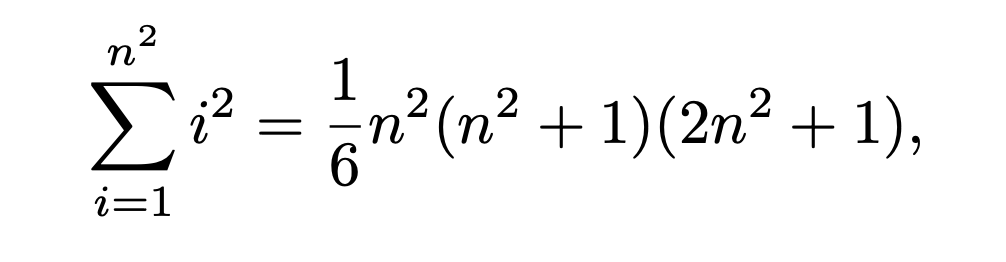
VAR
nk=hk=wk: Resolution of the VQ code map at step k, where h_k, w_k are the height and width.
n=h=w: Final resolution at step K.
Scaling factor a such that




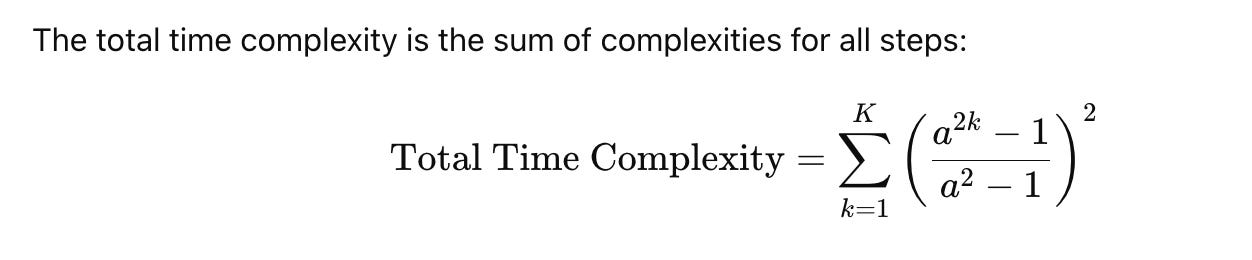
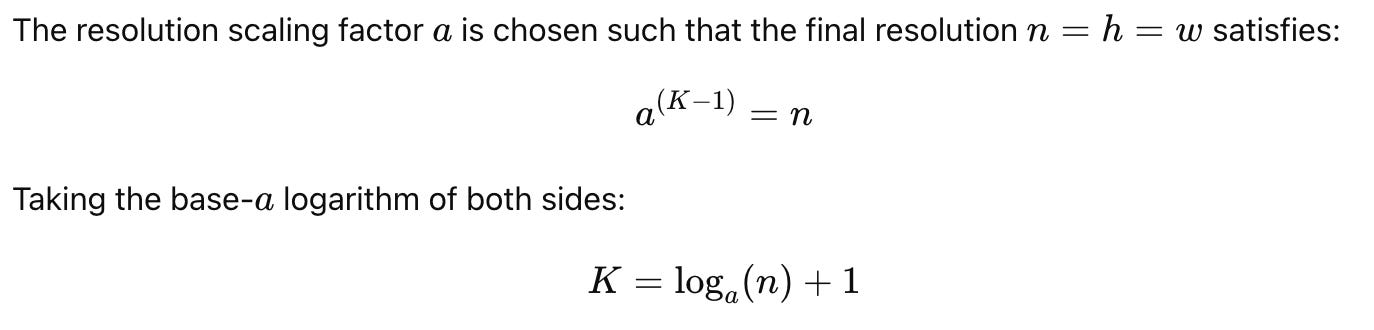


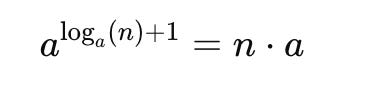
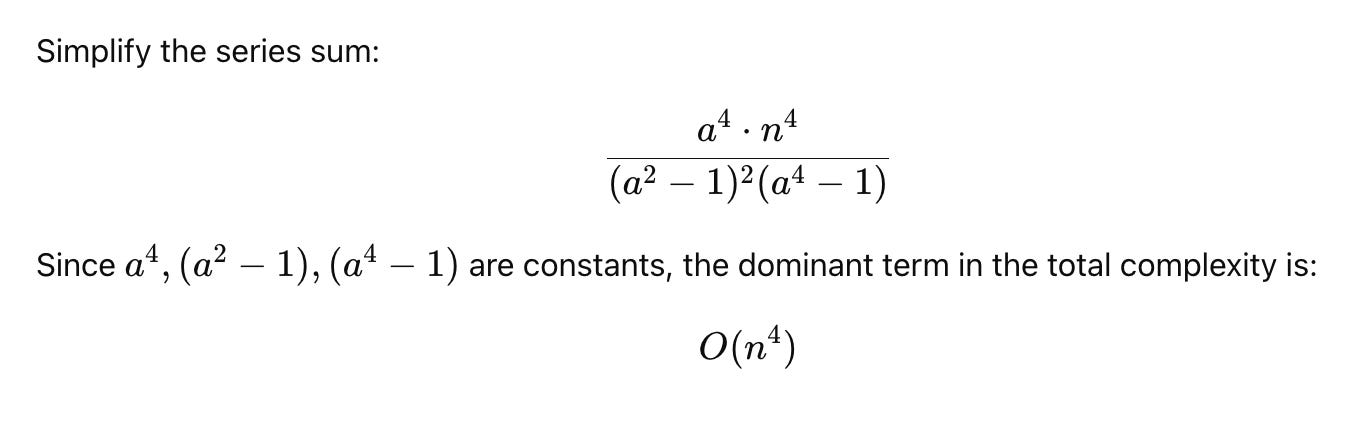
Intuition Behind VAR Complexity Reduction
Hierarchical Scaling:
Instead of generating n^2 tokens sequentially, VAR processes smaller resolutions iteratively, progressively refining the image.
Efficient Attention:
Self-attention focuses on fewer tokens per scale, and multi-scale context reduces the need for exhaustive pairwise comparisons.
Parallelism:
All tokens within a scale are generated in parallel, further reducing latency compared to AR’s strict sequential process.
VAR Tokenization Framework


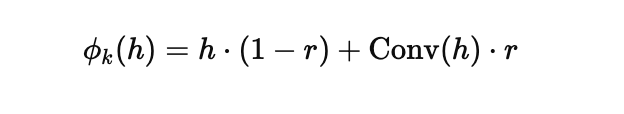
VAR Transformer Architecture
Causal Block Attention
In VAR, all tokens in the i-th scale can attend to previous tokens across scales, preserving contextual dependencies while generating tokens in parallel.




Scaling Laws in Visual Autoregressive Modeling (VAR)
Scaling laws describe how the performance of machine learning models improves as a function of the resources used, such as the number of parameters, computation, or data. These laws provide valuable insights into how to optimize model design, training strategies, and resource allocation for better performance. In the context of Visual Autoregressive Modeling (VAR), scaling laws are used to systematically improve model performance while balancing computational efficiency


Visual Autoregressive (VAR) models can indeed use rejection sampling and Classifier-Free Guidance (CFG), similar to MaskGIT.