
TPA Paper Explained
[Daily Paper Review: 16-01-25] Tensor Product Attention Is All You Need

The paper addresses a critical problem in modern large language models (LLMs): the memory and computational overhead associated with processing long input sequences during inference. Specifically, the issue stems from the storage of key-value (KV) caches, which grow linearly with sequence length. This limits the maximum context window that can be processed, as hardware constraints (e.g., GPU memory) become a bottleneck. The problem is particularly relevant for applications requiring long-context understanding, such as document analysis, complex reasoning, and code completion.
The Problem
Memory Overhead from KV Caches:
During inference, LLMs store key (K) and value (V) states for each token in the sequence to compute attention scores. This KV cache grows linearly with sequence length, leading to significant memory consumption.
For example, in a standard Transformer with multi-head attention (MHA), the memory required for KV caches scales as O(n⋅d)O(n⋅d), where nn is the sequence length and dd is the dimensionality of the model.
Scalability Challenges:
As models are scaled to handle longer sequences, the memory requirements for KV caches become impractical, limiting the maximum context window size.
This is a critical issue for applications that require processing long documents or maintaining context over extended interactions.
Existing Solutions and Their Limitations:
Sparse Attention Patterns: Reduce memory by computing attention only over a subset of tokens, but risk discarding important information.
Token Eviction Strategies: Remove less important tokens from the cache, but this can also lead to information loss.
Multi-Query Attention (MQA) and Grouped-Query Attention (GQA): Share keys and values across attention heads, reducing memory but sacrificing flexibility and requiring architectural changes.
Low-Rank Weight Factorization (e.g., LoRA): Reduces memory during fine-tuning but does not address KV cache overhead during inference.
Multi-head Latent Attention (MLA): Compresses KV representations but is incompatible with Rotary Position Embedding (RoPE), requiring additional parameters.
The Solution: Tensor Product Attention (TPA)
The paper proposes Tensor Product Attention (TPA), a novel attention mechanism that addresses the memory overhead problem by factorizing queries (Q), keys (K), and values (V) into compact, low-rank representations. This reduces the size of the KV cache while maintaining or even improving model performance.
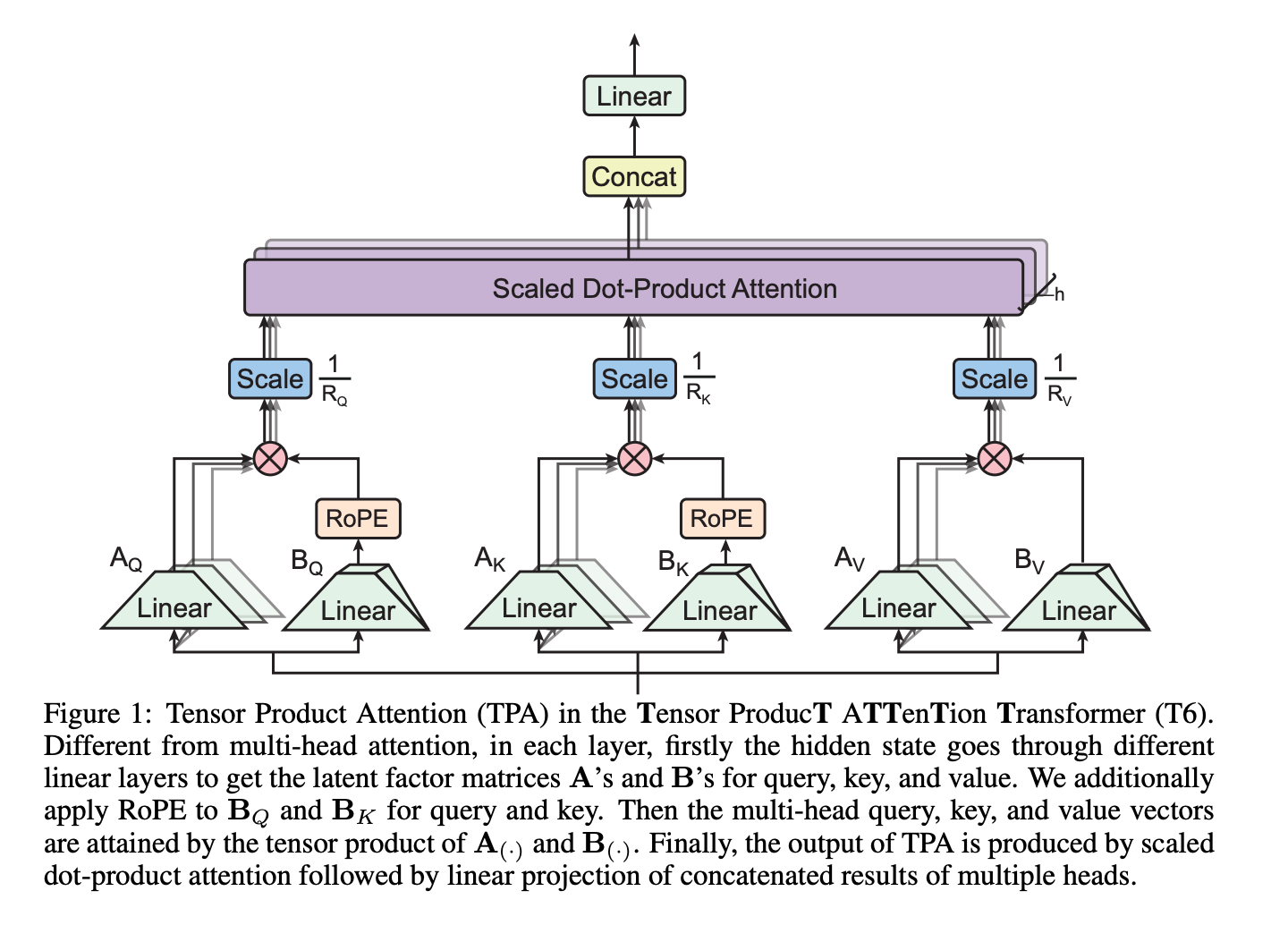
Key Ideas of TPA:
Contextual Tensor Decomposition:
TPA factorizes Q, K, and V into low-rank components using tensor decompositions. Unlike static weight factorization methods (e.g., LoRA), TPA performs dynamic factorization of activations, which adapts to the context of the input sequence.
This factorization reduces the memory required for KV caches by an order of magnitude (10× or more) compared to standard attention mechanisms.
Compatibility with RoPE:
TPA is designed to work seamlessly with Rotary Position Embedding (RoPE), a popular positional encoding method used in models like LLaMA and Gemma. This makes TPA a drop-in replacement for standard multi-head attention (MHA) layers in existing architectures.
Scaled Dot-Product Attention
Scaled Dot-Product Attention is the core mechanism used in Transformers to compute attention scores between tokens in a sequence. It determines how much focus (or "attention") each token should give to other tokens in the sequence.

Multi-Head Attention (MHA)
Multi-Head Attention extends Scaled Dot-Product Attention by using multiple attention heads. Each head learns a different projection of the input, allowing the model to capture diverse types of relationships between tokens.

Multi-Query Attention (MQA)
Multi-Query Attention (MQA) is a memory-efficient variant of Multi-Head Attention (MHA) that reduces the memory overhead of storing keys and values during inference. It achieves this by sharing keys and values across all attention heads, while still maintaining unique query projections for each head.

Key Features:
Memory Efficiency: By sharing keys and values, MQA significantly reduces the memory required for the key-value (KV) cache during inference. This is especially beneficial for long sequences.
Expressivity Trade-off: Since all heads share the same keys and values, MQA loses some expressivity compared to MHA, where each head has its own unique keys and values.
Grouped Query Attention (GQA)
Grouped Query Attention (GQA) is a generalization of MHA and MQA that groups attention heads and shares keys and values within each group. This allows GQA to interpolate between the memory efficiency of MQA and the expressivity of MHA.

Rotary Position Embedding (RoPE)
Rotary Position Embedding (RoPE) is a positional encoding method used to inject positional information into the query and key vectors in attention mechanisms. Unlike traditional positional embeddings (e.g., sinusoidal embeddings in the original Transformer), RoPE encodes positional information through rotations in the vector space.
Motivation:
Positional information is crucial for Transformers to understand the order of tokens in a sequence.
RoPE provides a way to encode positions that preserves relative positional relationships (translation invariance) while being computationally efficient.

Multi-head Latent Attention (MLA)
Multi-head Latent Attention (MLA) is a memory-efficient attention mechanism used in models like DeepSeek-V2 and DeepSeek-V3. It reduces the memory overhead of key-value (KV) caching during inference by compressing keys and values into low-rank representations.
Motivation:
Storing full key and value matrices for long sequences is memory-intensive, especially during autoregressive decoding.
MLA addresses this by compressing keys and values into low-rank latents, reducing the memory footprint while preserving performance.


Key Features:
Memory Efficiency: By compressing keys and values into low-rank latents, MLA significantly reduces the memory required for KV caching during inference.
RoPE Compatibility: MLA introduces a separate set of RoPE-transformed keys K_R to ensure compatibility with rotary position embeddings.
Performance Preservation: Despite the compression, MLA largely preserves the performance of standard multi-head attention.


Tesnor Product Attention (TPA)
The core idea of TPA is to factorize the queries QQ, keys KK, and values VV into low-rank components. This reduces memory usage while preserving the ability to compute attention scores effectively.



RoPE Compatibility and Acceleration
Rotary Position Embedding (RoPE) is used to encode positional information into queries and keys. TPA integrates RoPE seamlessly by pre-rotating the token-dimension factors.

Memory Efficiency in TPA
TPA reduces memory consumption during inference by:
Low-Rank Factorization:
Queries, keys, and values are represented using low-rank components, significantly reducing the size of the key-value (KV) cache.
Pre-Rotated Keys:
By pre-rotating the keys, TPA avoids the need to store full keys and values, further reducing memory usage.

Tensor ProducT ATTenTion Transformer (T6)

1. Dataset and Training Setup
Dataset: FineWeb-Edu 100B (100B training tokens, 0.1B validation tokens).
Baselines: Compared T6 (TPA-based) against LLaMA (MHA, MQA, GQA, MLA) with SwiGLU and RoPE.
Model Scales: Small (124M), Medium (353M), Large (773M) parameters.
Training: AdamW optimizer, cosine annealing scheduler, gradient clipping, and batch size of 480.
2. Key Results
Training and Validation Loss:
TPA and TPA-KVonly converge faster and achieve lower losses than MHA, MQA, GQA, and MLA.
MLA trains slower and yields higher losses.
Validation Perplexity:
TPA-based models (TPA and TPA-KVonly) achieve the lowest perplexities across medium and large scales.
Outperforms MHA, MQA, GQA, and MLA by the end of pretraining (~49B tokens).
Downstream Evaluation:
Medium Models (353M):
TPA outperforms MHA, MQA, and MLA in zero-shot (51.41% vs. 50.11%, 50.44%, 48.96%) and two-shot (53.12%) tasks.
Large Models (773M):
TPA-KVonly achieves the highest accuracy (53.52% zero-shot, 55.33% two-shot), closely followed by TPA.