
Toto Paper Explained
[Daily Paper Review: 09-01-25] An Empirical Study of Autoregressive Pre-training from Videos

The paper presents a study on autoregressive pre-training for videos, inspired by earlier works in information theory and image modeling. The researchers introduce a framework, called Toto, to model videos as sequences of visual tokens using a causal transformer architecture. This approach allows them to apply autoregressive methods, commonly used in language models, to video and image data. Below is a detailed breakdown:

Proposed Framework: Toto
Video Tokenization:
dVAE is used to tokenize video frames into discrete visual tokens.
Treating videos as sequences of tokens unifies the modeling approach for videos and images.
Architecture:
Uses the LLaMa architecture, a causal transformer model, for next-token prediction.
Dataset:
Composed of over 1 trillion visual tokens from diverse video and image data.
Enables joint training on both videos and images.
Evaluation:
Evaluated on downstream tasks such as:
Image and video recognition.
Video forecasting.
Semi-supervised tracking.
Object permanence tasks.
Robotics tasks in simulation and real-world settings.
Approach
Objective:
Train a causal transformer to predict the next patch token in sequences derived from images and videos.
This task is analogous to next-token prediction in language models.
Tokenization:
Images and videos are divided into small patches.
Each patch is converted into a discrete token using a raster scan ordering (left-to-right, top-to-bottom scanning).
The result is a 1D sequence of tokens for each sample.
Pre-training:
The model learns to estimate the density p(x_j) of tokens using the conditional probability:

Minimize the negative log-likelihood (NLL) loss:



Architecture
Transformer Setup:
The model employs a causal transformer (unidirectional attention).
Inspired by LLaMa architecture
Key Features:
Pre-normalization: Uses RMSNorm
Activation: Uses SwiGLU
Positional Embeddings: Uses RoPE
Transformer Layers:
For each transformer layer l:

Model Variants:
Base: 120M parameters, 12 layers, 12 attention heads, 768 hidden dimensions.
Large: 280M parameters, 16 layers, 16 attention heads, 1024 hidden dimensions.
1B: 1.1B parameters, 22 layers, 16 attention heads, 2048 hidden dimensions.
Optimization:
Optimizer: AdamW with:

Schedule: Cosine learning rate decay after 2000 warm-up steps.
Batch size: 1M tokens per batch.
Training Configuration
Context Length: Models are pre-trained on sequences of 4096 tokens.
Special Tokens:
Videos use
[1]as the start token.Images use
[3]as the start token.All sequences end with
[2].

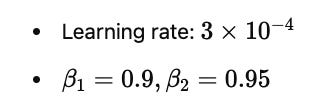
Tokenization with dVAE
Tokenizer Used: The dVAE tokenizer from DALL-E is employed, offering an 8k-token vocabulary.
Reason for Choice:
Supports both images and videos, making it versatile for downstream tasks.
VQGAN provides sharper images but incorporates ImageNet label biases due to perceptual loss, which dVAE avoids.
Tokenization Process:
Each image or frame is resized to 128x128 and tokenized into 16x16 discrete tokens, resulting in 256 tokens per image or video frame.
For videos:
Frames are sampled every 4 frames, creating a sequence of 16 frames (T=16) equivalent to 4096 tokens.
For images:
16 images are grouped into a sequence, also forming 4096 tokens.
Comparison of Tokenization Methods:
dVAE vs. VQGAN:
dVAE provides broader token coverage ~ 100% compared to VQGAN < 50%.
Both show similar performance for the same resolutions.
Patch-Based Tokenization:
Slightly worse accuracy than dVAE/VQGAN methods.
ImageNet Probing Accuracy (Table 3):
dVAE with 8k tokens and 16x16 resolution achieves 53.2% top-1 accuracy.
dVAE with 8k tokens and 32x32 resolution achieves 61.2%.
Fine-tuning low-resolution models (e.g., 16x16) to higher resolutions (e.g., 32x32) boosts performance, achieving up to 64.4%.
Resolution Impact:
Higher resolution (256x256) results in more tokens (1024) and higher computational cost.
Training on lower resolution (128x128) reduces tokens to 256 and makes training cheaper but results in a drop in performance.
Fine-Tuning:
Models pre-trained at lower resolution can be fine-tuned at higher resolutions with relative positional embeddings (RoPE).
This not only improves accuracy (e.g., 63.2%) but also reduces overall training cost.
Using higher base values for RoPE embeddings (10,000 to 50,000) further enhances performance.
Attention Pooling vs. Average Pooling
Attention pooling outperforms average pooling when aggregating intermediate tokens.
Key Steps in Attention Probing:
Query Token:
A query token is introduced to "probe" the intermediate representations of the model.
This query token cross-attends to all other tokens in the representation (using an attention mechanism).
Learning Attention Matrices:
To compute the attention, the query token learns two matrices:
Wk (Key matrix): Encodes "what is relevant" in the intermediate tokens.
Wv(Value matrix): Encodes "how much to pay attention" to those tokens.
These matrices determine how much weight each token contributes to the final representation.
Attention Mechanism:
Using the learned matrices, the query token interacts with all intermediate tokens and combines them into a single output vector.
This output is an attention-weighted summary of the representation, emphasizing the most informative tokens.
Why Not Average Pooling?
In average pooling, all tokens contribute equally to the final representation.
This uniform weighting can be suboptimal, especially in tasks where some tokens (e.g., those with more context or semantic richness) are more important than others.
Attention probing addresses this limitation by dynamically weighting tokens based on their importance.
Downstream Tasks and Pre-trained Model Transfer
Behavior of Layers:
Decoder-only Models: Best performance is observed in middle layers (due to focus on reconstruction in later layers).
Encoder-Decoder Models: Optimal features are at the top of encoder layers because of the structural imbalance.
Evaluation of Downstream Tasks
1. Image Recognition (ImageNet-1k)
Setup:
Evaluated with probing at each layer using attention pooling.
Fine-tuned with a self-supervised next-token prediction loss and cross-entropy loss on the probing layer.
Uses 32×32 token resolution.
Incorporates RoPE (Rotary Positional Encoding) embeddings with extended base value (10,000 → 50,000) for better performance at larger resolutions.
Findings:
Instance discriminative models (e.g., SimCLR, DINO) perform better than generative models for classification tasks.
Generative models (e.g., iGPT) achieve comparable performance despite being designed for modeling data distribution.
2. Action Recognition (Kinetics-400)
Setup:
Videos evaluated with 128×128 resolution for token budget consistency.
Model probes layers to identify the optimal representation for action classification.
Findings:
Generative models perform competitively, although discriminative models excel in this task.
3. Action Forecasting (Ego4D Dataset)
Task: Predict future actions (interaction object, type, and time to contact).
Approach:
Backbone from the pre-trained model integrated with a pyramid network (e.g., StillFast).
Extracts tokens at 5 layers, fuses features, and fine-tunes using a combination of self-supervised loss and task-specific losses.
4. Video Tracking (DAVIS Dataset)
Uses label propagation without requiring fine-tuning or probing.
Finds the nearest neighbor patch in the current frame from the last nnn frames.
Evaluates against models like DINO and MAE for performance on mask propagation.
Compute Optimal Scaling in Toto
µ-Parameterization:
Training used the µ-Parameterization approach (Yang et al., 2022).
Optimal learning rate for all model widths was found to be 2⁻⁷.
Scaling Law Observations:
A clear power law relationship was observed between compute and validation loss:

Interpretation:
Toto's scaling coefficient (-0.0378) is less steep than GPT-3's (-0.048), indicating slower improvement in loss with added compute.

Some Concepts


