
STAR Paper Explained
[Daily Paper Review: 07-01-25] STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution

For video super resolution, these days we are trying Image diffusion models, which solving the over smoothing issue in GAN.
What Causes Over-Smoothing in GANs?
Pixel-wise Loss Optimization
Many GANs, especially those trained with auxiliary pixel-wise losses (like L2 or L1), focus on minimizing the average difference between generated and ground truth pixels. These pixel-wise losses are biased toward producing the "mean" of possible outputs, which lacks high-frequency details and leads to smoother but less realistic results.Mode Collapse
GANs sometimes suffer from mode collapse, where the generator focuses on a limited subset of the data distribution. This can cause repetitive or overly smoothed patterns in the outputs, as the generator fails to produce diverse and sharp results.Limited High-Frequency Detail Recovery
GANs are often challenged to accurately reconstruct fine details and high-frequency components (like textures) of images or videos, especially when working with low-resolution inputs. Instead of generating plausible details, the generator might opt for safer, smoothed approximations.Weak Discriminator Signal
If the discriminator fails to effectively differentiate between sharp, detailed outputs and overly smooth ones, the generator won't be penalized for producing blurred or smoothed results. This can happen if the training data lacks sufficient variety or if the discriminator is not well-optimized.
How Diffusion models tackle this problem?
Process Overview: Diffusion models start with pure noise and iteratively refine it through a series of denoising steps to produce a detailed output. Each step adds or refines high-frequency details, ensuring sharp textures and avoiding the overly smoothed appearance common in GANs.
High-Frequency Recovery: By sampling from the data distribution at each step, diffusion models naturally incorporate realistic details instead of averaging pixel values as GANs often do.
The step-by-step denoising process inherently allows:
Fine-grained control over details: Each step can refine textures and structures without introducing artifacts.
Rejection of Over-Smoothing: As noise is removed iteratively, the model can balance smoothness and sharpness, preserving essential details.
However these image based diffusion models strugged to maintain temporal consistency. incorporating temporal blocks or optical flow maps to improve temporal information capture. However, since these models are primarily trained on image data rather than video data, simply adding temporal layers often fails to ensure high temporal consistency. So Integrating Text to Video (T2V) model into video super-resolution for improved temporal consitency. But still has two issues:
artifacts introduced by complex degradations in real-world scenarios
compromised in quality due to the strong generative capacity of powerful T2V models
The paper STAR introduces a novel framework that integrates advanced diffusion models, local enhancement techniques, and dynamic frequency loss functions to address these challenges.

Key Contributions
Integration of Diffusion Priors:
STAR is the first framework to incorporate powerful text-to-video (T2V) diffusion priors for real-world VSR.
The diffusion model improves spatial detail restoration and enhances temporal consistency.
Local Information Enhancement Module (LIEM):
A novel module that prioritizes local information, addressing the limitations of global attention mechanisms.
LIEM reduces artifacts and improves fine-grained details.
Dynamic Frequency (DF) Loss:
A loss function that decouples the optimization of low- and high-frequency fidelity, dynamically adjusting focus across diffusion steps.
Ensures better reconstruction of both large structures and fine textures.
State-of-the-Art Results:
Achieves the highest clarity (DOVER scores) and robust temporal consistency across benchmark datasets.


Local Information Enhancement Module (LIEM)
Motivation
Most T2V models rely on global attention mechanisms, which:
Aggregate features over the entire video, often failing to handle local degradations effectively.
Struggle to preserve fine local details, leading to blurry outputs.
To address these shortcomings, LIEM focuses on local information enhancement before applying global attention.

The expression
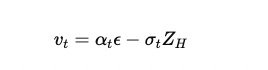
comes from the velocity prediction objective in diffusion models. It reflects a fundamental aspect of how diffusion models represent the generation process in latent space during the denoising process. Let’s break it down step-by-step:

Dynamic Frequency Loss (DF Loss)
Motivation
The STAR framework aims to balance low-frequency fidelity (large structures and shapes) and high-frequency fidelity (details like edges and textures) during video super-resolution. Diffusion models naturally follow a two-phase process during inference:
Early diffusion steps: Focus on reconstructing low-frequency components (global structure).
Later diffusion steps: Emphasize high-frequency components (details and textures).
The Dynamic Frequency Loss (DF Loss) is designed to leverage this behavior:
Low-frequency fidelity is prioritized early in the diffusion process.
High-frequency fidelity becomes more critical in later steps.
This decouples fidelity requirements, simplifies optimization, and ensures both structural coherence and fine detail restoration.


Key Advantages of DF Loss
Adaptive Fidelity Prioritization:
Early diffusion steps focus on reconstructing global structures.
Later steps refine details like textures and edges.
Simplified Optimization:
By decoupling low- and high-frequency fidelity, DF Loss simplifies the learning process and reduces conflicts between global structure and fine details.
Improved Results:
Balances structural accuracy and detail preservation, enhancing the overall quality of the super-resolved videos.
ChatGPT said:
ChatGPT
Training Summary
Datasets
OpenVid-1M Subset:
A high-quality dataset of 1 million in-the-wild video clips with captions.
Used a subset of ~200K text-video pairs.
Videos have a minimum resolution of 512×512, with an average duration of 7.2 seconds.
Degradation Process:
LR-HR (low-resolution and high-resolution) video pairs were generated using the degradation strategy from Real-ESRGAN.
Video compression operations were added to simulate severe real-world degradation, inspired by RealBasicVSR.
Training Details
Backbone: I2VGen-XL (text-to-video generation model).
Initialization: Pre-trained weights from VEnhancer were used for faster convergence.
Adaptations:
ControlNet and the Local Information Enhancement Module (LIEM) were trained to fine-tune the T2V model for real-world video super-resolution (VSR) tasks.
Results

DOVER (Detail-Oriented Video Restoration): Higher indicates better clarity and temporal consistency.
E*warp: Lower indicates better temporal stability.