
rStar Paper Explained
[Daily Paper Review: 10-01-25] rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking

rStar-Math, a novel approach to improving mathematical reasoning in large language models (LLMs). Let’s break it down step by step, explaining the motivations, methods, and significance:
LLMs and Mathematical Problems: Large language models have shown some ability to solve mathematical problems. However, conventional approaches often mimic System 1 thinking (quick, intuitive, and error-prone reasoning). These models generate solutions in a single pass, leading to errors.
Need for System 2 Thinking: Inspired by human cognitive processes, System 2 thinking is slower, deeper, and more deliberate. It involves breaking problems into smaller steps and iteratively refining the solution.
Challenges with Current Techniques:
Training data relies on high-quality Chain-of-Thought (CoT) reasoning, typically distilled from larger LLMs like GPT-4.
Hard problems unsolvable by the teacher LLMs are excluded, limiting progress.
Even solvable problems often have error-prone intermediate steps, which are hard to detect and improve.
Scaling up CoT datasets shows diminishing returns: for example, an 8× increase in dataset size yielded only a 3.9% improvement on some benchmarks.
At test time, new techniques involve generating multiple solutions and selecting the best using reward models. However:
Open-source methods for this scaling struggle due to limitations in policy LLMs (models generating reasoning) and reward models (models evaluating solutions).
This bottleneck constrains the effectiveness of math reasoning improvements.
Reward models are critical in guiding a language model to perform System 2 reasoning, which involves deeper, iterative thought processes. What is the problem?
Step-Level Reward Annotation is Hard to Obtain:
Traditional Process Reward Models (PRMs) evaluate the quality of reasoning steps, providing dense, detailed feedback for every step in solving a problem.
However, annotating such detailed step-level rewards often requires costly human annotations, such as datasets like PRM800k.
Automated Annotation Struggles with Precision:
Newer methods attempt to replace human annotations with automated approaches, like Monte Carlo Sampling or Monte Carlo Tree Search (MCTS).
These methods generate scores for reasoning steps, but the scores are often noisy and imprecise, leading to suboptimal results.
Result:
Current methods for step-level annotation (whether human-driven or automated) have limitations in precision, scalability, or cost, which restrict the performance improvement in reasoning tasks.
The Proposed Solution: rStar-Math
rStar-Math addresses these challenges by introducing self-evolvable System 2 reasoning with three key innovations.
Code-Augmented CoT Data Synthesis
Process Preference Model (PPM)
Self-Evolution
Key Concepts and Goals
System 2 Reasoning: Refers to complex, step-by-step, logical reasoning, often necessary for solving intricate math problems.
Monte Carlo Tree Search (MCTS): A search algorithm that explores possible actions step-by-step, assigning values (Q-values) to each step based on its contribution to the solution. This method makes the task simpler by focusing on one step at a time, rather than generating the full solution at once.
Policy Model (SLM): A language model trained to generate solutions for individual steps in the problem-solving process.
Process Reward Model (PRM): Evaluates the quality of intermediate steps to guide the policy model during training.
Why MCTS for System 2 Reasoning?
Breaks Down Complexity:
Solving a problem step-by-step is easier than solving it in one shot (e.g., Best-of-N or self-consistency approaches require generating full solutions).
By focusing on one step at a time, MCTS reduces the difficulty of the task for the policy model.
Step-Level Training Data:
MCTS naturally generates training data for both the policy model and the reward model.
It assigns Q-values (a numerical score) to each step, based on how much it contributes to solving the problem correctly.
This removes the need for expensive human annotations to evaluate individual steps.
Challenges in Using MCTS with Advanced Models (like GPT-4)
Limited Problem Diversity:
Advanced models like GPT-4 often fail to solve difficult problems (e.g., Olympiad-level math).
As a result, the training data generated consists mostly of simpler problems, which lack diversity and quality.
Spurious Q-Value Assignments:
Proper Q-value assignment depends on extensive MCTS rollouts (iterations of step-by-step exploration).
Insufficient exploration may lead to incorrect Q-values, such as overestimating suboptimal steps.
High Computational Cost:
Advanced models are computationally expensive, and each MCTS rollout involves generating multiple single steps.
Increasing the number of rollouts significantly raises inference costs.
Proposed Solution
Step 1: Use Smaller Models (7B SLMs)
Instead of relying on advanced but expensive models like GPT-4, two smaller 7B models are used:
Policy Model: Generates step-by-step reasoning.
Reward Model: Evaluates the quality of intermediate steps.
Why Smaller Models?
They are computationally efficient, allowing for extensive MCTS rollouts on accessible hardware (e.g., 4×40GB A100 GPUs).
This enables better exploration and more reliable Q-value assignment.
Step 2: Address SLM Limitations
Issue with SLMs:
Smaller models are weaker and often fail to produce correct solutions or high-quality intermediate steps.
They solve fewer challenging problems compared to advanced models.
Solution: Code-Augmented Chain-of-Thought (CoT)
A synthetic method where reasoning trajectories (step-by-step solutions) are generated with the help of code augmentation.
Extensive MCTS rollouts verify each reasoning trajectory, annotating steps with Q-values.
This ensures that only verified, high-quality steps are used for training.
Step 3: Progressive Self-Evolution
To improve the performance of the SLMs and tackle more difficult problems:
Four-Round Self-Evolution:
In each round, the policy model and the reward model are updated to stronger versions.
This is done by using the training data generated in the previous round to improve the models.
Why Self-Evolution?
It helps models handle more challenging problems over time.
Training data quality improves with each round, as stronger models generate better solutions.
Step 4: Novel Process Reward Model (PRM) Training
Problem with Traditional PRM Training:
Traditional PRM training requires precise Q-values for every step, which are hard to annotate accurately.
Errors in Q-value assignments can degrade performance.
Solution: Process Preference Model (PPM):
Instead of relying on precise Q-values, the PPM uses relative preferences.
It determines which steps are better (positive) or worse (negative) compared to others.
This pairwise ranking eliminates the need for precise step-level annotations while still providing effective guidance.
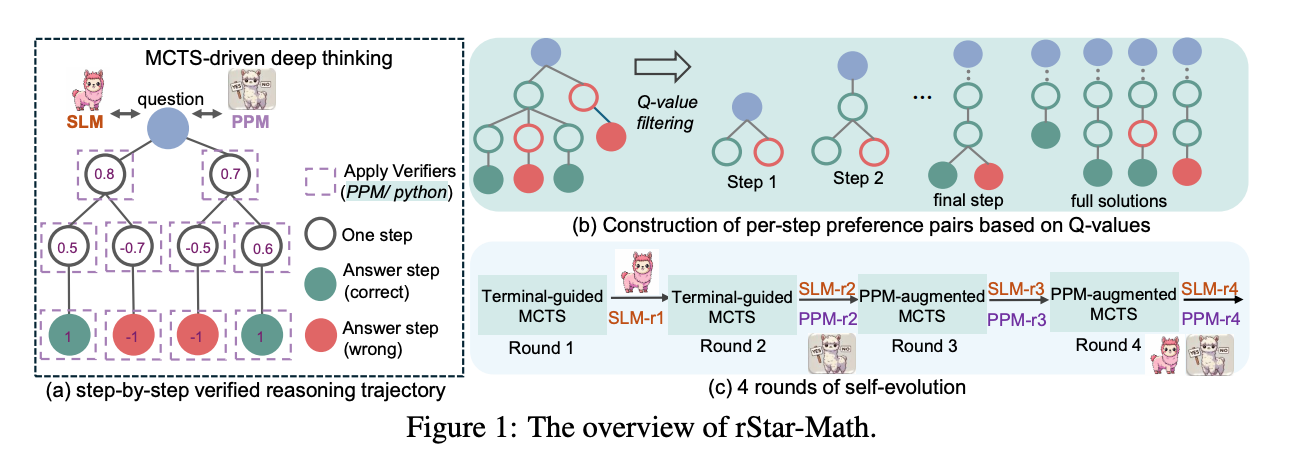
The approach aims to solve math problems by generating high-quality training data for models using Monte Carlo Tree Search (MCTS). It achieves this by constructing step-by-step verified reasoning trajectories, annotating each step with a quality score or Q-value, and refining the models through multiple rounds of evolution. Here's the breakdown of the key components:



The Process Preference Model (PPM) is designed to evaluate and rank intermediate reasoning steps during problem-solving, addressing challenges in providing granular step-level reward signals. Let’s break this into detailed components, diving into the math and concepts involved.
Solving complex problems often requires reasoning step by step. To evaluate each step:
Existing methods assign scores to steps via human annotations or MCTS-generated scores.
These scores are used as training targets in loss functions like Mean Squared Error (MSE) or pointwise loss.
However, precisely evaluating and ranking step quality is difficult:
Among correct steps, differentiating "best" from "average" is challenging.
Among incorrect steps, distinguishing "bad" from "moderately bad" steps is also hard.
Proposed Solution: Preference-Based Approach
Instead of assigning exact scores to steps, the PPM focuses on relative preferences between steps:
Positive Steps: Steps with high Q-values leading to correct final answers.
Negative Steps: Steps with low Q-values leading to incorrect final answers.
Preference Pairs: For each intermediate step, two positive steps and two negative steps are chosen to form pairs for training.
Construction of Preference Pairs
Intermediate Steps
For any intermediate step iii, positive and negative steps:
Share the same preceding steps (from the root node to step i−1).
Positive steps y_i_pos are among the highest Q-valued steps.
Negative steps y_i_neg are among the lowest Q-valued steps.
Final Answer Step
The final answer step doesn't always have identical preceding trajectories. Hence:
Positive steps are trajectories with the highest average Q-values leading to correct answers.
Negative steps are trajectories with the lowest average Q-values leading to incorrect answers.
Loss Function

Trajectory Definitions

Training and Evaluation
Training Dataset Construction:
Use MCTS rollouts to compute Q-values for all steps.
Construct positive-negative preference pairs based on these Q-values.
Training Objective:
Train the PPM to predict higher scores for positive steps compared to negative ones, based on L_PPM.
Evaluation:
Evaluate PPM's ability to rank steps correctly.
Use the trained PPM to guide reasoning trajectories in future tasks.
Iterative Self-Evolution
Each round of self-evolution uses MCTS to generate reasoning trajectories, trains the models, and prepares them for the next round.
Round 1 (Bootstrap):
Train an initial policy model (SLM-r1) with limited MCTS rollouts (8 per problem).
Train an initial preference model (PPM-r1) but with limited reliability due to noisy Q-values.
Round 2:
Use the improved policy model (SLM-r1) to generate more reliable reasoning trajectories (16 MCTS rollouts).
Train a better preference model (PPM-r2) with higher-quality Q-values.
Round 3:
Use PPM-augmented MCTS to guide trajectory generation.
Significantly improve trajectory quality for harder problems (e.g., Olympiad-level).
Train SLM-r3 and PPM-r3 for further improvements.
Round 4 (Final):
Focus on solving the hardest remaining problems.
Increase MCTS rollouts to 64 or even 128 for unsolved problems.
Expand MCTS trees with different random seeds to boost diversity.
Achieve 90.25% coverage of the dataset.
Key Components
1. Monte Carlo Tree Search (MCTS)
Purpose: Generate reasoning trajectories for math problems.
How It Works:
Tree Structure: Represents possible reasoning steps for a problem.
Rollouts: Simulate multiple trajectories (paths) by exploring possible reasoning steps.
Q-Values: Each step in a trajectory is scored based on correctness and utility.
Correct answers yield higher Q-values.
Incorrect or suboptimal steps yield lower Q-values.
Output: Verified step-by-step reasoning trajectories with Q-values.
Why MCTS is Used:
MCTS ensures that only high-quality, step-by-step solutions are included for training.
2. Policy Reasoning Model (PRM)
Purpose: Predict the next reasoning step in solving a math problem.
Training:
Initialized using supervised fine-tuning (SFT) with reasoning trajectories from MCTS.
Input: A reasoning trajectory up to the current step.
Output: Predicts the next step.
Updates:
Iteratively fine-tuned with top trajectories (based on Q-values) generated in each round of MCTS.
Only trajectories leading to correct solutions are used for SFT.
3. Preference Model (PPM)
Purpose: Evaluate and rank the quality of reasoning steps (positive or negative).
Training:
Initialized from the PRM but with a different output head.
A scalar value head predicts scores in [−1,1][-1, 1][−1,1] for step quality.
Input: Pairs of reasoning steps from MCTS rollouts.
Positive Examples: Steps with high Q-values.
Negative Examples: Steps with low Q-values.
Output: Scores reasoning steps to filter out poor trajectories.
Role in MCTS:
Used to augment MCTS by prioritizing trajectories with high-quality reasoning steps.
Why Verified Reasoning Trajectories Matter
Step-by-step verified reasoning helps improve the accuracy of math problem solving because it ensures that each step taken in the reasoning process is correct.
The use of MCTS (Monte Carlo Tree Search) to augment the PPM (Process Reward Model) enables dense verification during the solution generation. This makes the model's reasoning process more reliable compared to methods that rely on random generation or rejection sampling.
As a result, rStar-Math's verified trajectories not only eliminate intermediate errors but also generate more challenging problems for training, ultimately improving the model’s ability to solve harder problems.
Results
