
LTX-Video Paper Explained
[Daily Paper Review: 17-01-25] LTX-Video: Realtime Video Latent Diffusion

Video generation is a complex task due to the need for temporal consistency (ensuring smooth transitions between frames) and high-resolution output (preserving fine details). Existing methods often rely on spatiotemporal transformers and 3D VAEs (Variational Autoencoders) for video generation, but they face several limitations:
Inefficient Interaction Between Components: Existing models treat the Video-VAE (responsible for compression) and the denoising transformer (responsible for generating clean latents) as independent components. This separation leads to suboptimal performance and inefficiencies.
High Computational Cost: Generating high-resolution videos with temporal consistency requires significant computational resources, especially when applying full spatiotemporal self-attention across frames.
Loss of Fine Details: High compression ratios in the latent space often result in the loss of fine details, as the compressed latent space cannot fully represent high-frequency information.
Slow Generation Speed: Many existing models are slow, taking longer than real-time to generate videos, which limits their practical applicability.
The Solution: LTX-Video
LTX-Video proposes a holistic approach to video generation by integrating the Video-VAE and denoising transformer into a single, optimized framework. The key innovations are:
A. Holistic Integration of Video-VAE and Denoising Transformer
B. Novel Video-VAE Design
C. Transformer Enhancements
Fast and Scalable Generation
Faster-than-Real-Time Generation: LTX-Video is capable of generating 5 seconds of 24 fps video at 768×512 resolution in just 2 seconds on an Nvidia H100 GPU. This is faster than real-time and outperforms all existing models of similar scale (2B parameters).
Diverse Use Cases: The model supports text-to-video and image-to-video generation, with both capabilities trained simultaneously. It uses a timestep-based conditioning mechanism to condition the model on any part of the input video without requiring additional parameters or special tokens.
Detailed Method
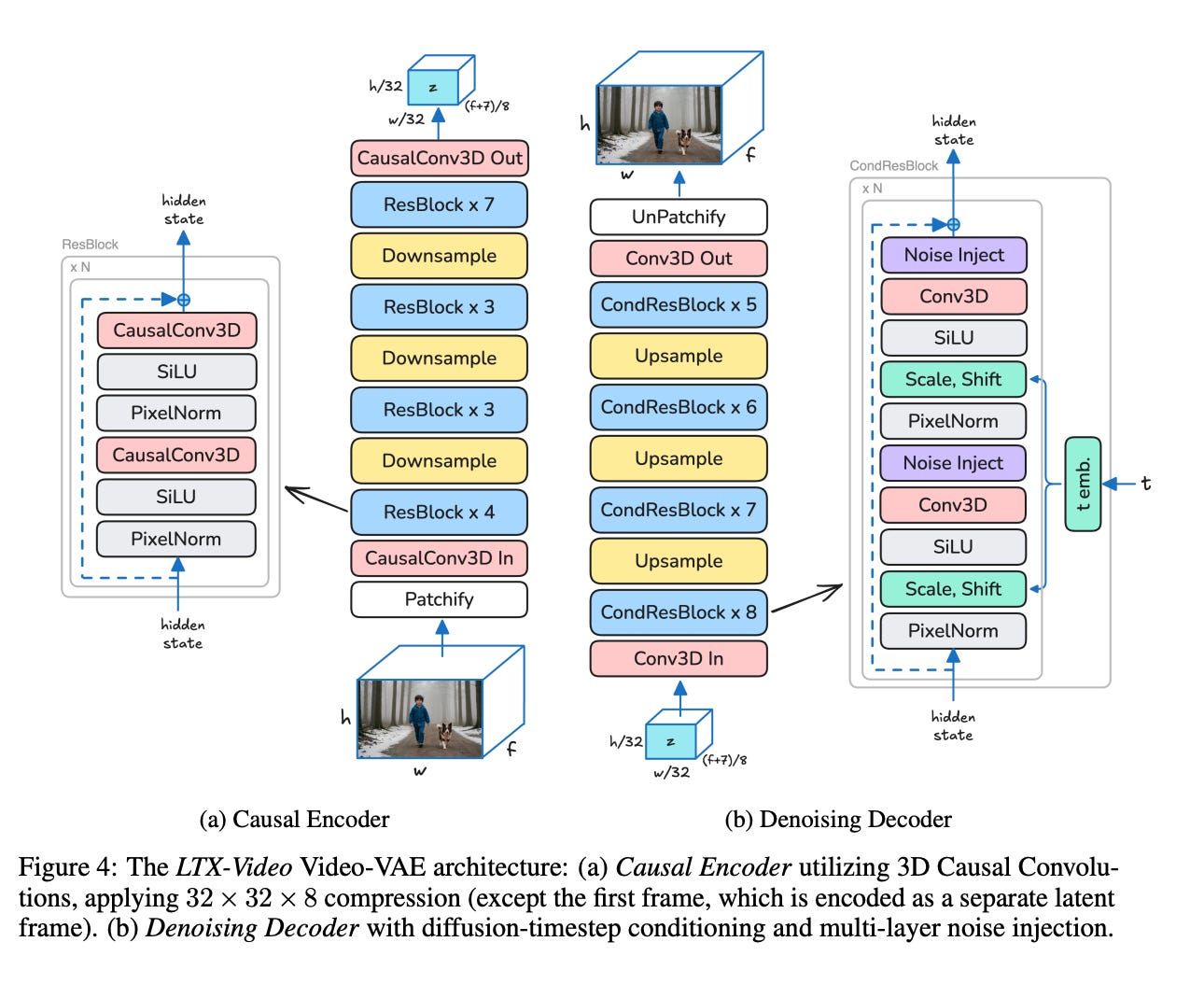
The Video VAE (Variational Autoencoder) in LTX-Video is a critical component that enables high compression of video data while maintaining high visual quality and temporal consistency. Below, I will explain the Video VAE in detail, step by step, including its architecture, design choices, and how it achieves high compression without sacrificing quality.
1. Overview of Video VAE
The Video VAE is responsible for compressing the input video into a latent space and then reconstructing it back into pixel space. The key innovation in LTX-Video is the high compression ratio of 1:192, which is achieved through spatiotemporal downscaling of 32×32×8 pixels per token. This high compression enables the transformer to operate efficiently in the latent space, reducing computational costs while maintaining video quality.
2. Key Design Choices
The Video VAE in LTX-Video introduces several key enhancements over traditional VAEs:
A. High Compression Ratio
Compression Factor: The Video VAE achieves a compression ratio of 1:192, meaning that every token in the latent space represents 32×32×8 pixels in the original video. This is twice the compression of typical VAEs used in recent models (e.g., CogVideoX, MovieGen), which achieve a compression ratio of 1:48 or 1:96.
Pixels-to-Tokens Ratio: The effective pixels-to-tokens ratio is 1:8192, which is four times higher than typical models. This is achieved without requiring a patchifier (a module that groups latent patches into tokens), simplifying the architecture and improving efficiency.
B. High Latent Depth
128 Channels: The latent space has a depth of 128 channels, which is significantly higher than traditional VAEs (e.g., 16 channels in CogVideoX). This allows the VAE to capture more information in the latent space, enabling higher spatial compression while maintaining video quality.
C. Relocation of Patchifying Operation
Patchifying at VAE Input: Unlike traditional models that apply patchifying at the transformer input, LTX-Video relocates this operation to the VAE input. This means the VAE directly processes 32×32×8 pixel patches, reducing redundancy and improving efficiency.
3. Architecture of Video VAE
The Video VAE consists of two main components: the encoder and the decoder. Below, I will explain each component in detail.
A. Encoder
The encoder compresses the input video into a latent representation. Its key features are:
Input Patchifying:
The input video is divided into 32×32×8 pixel patches. Each patch is processed independently, reducing the spatial and temporal dimensions of the video.
Convolutional Layers:
The encoder uses 3D convolutional layers to downsample the video spatially and temporally. These layers extract features from the input patches and reduce their dimensionality.
Latent Space Representation:
The output of the encoder is a high-dimensional latent space with 128 channels. This latent representation captures the essential features of the video while significantly reducing its size.
B. Decoder
The decoder reconstructs the video from the latent representation. Its key features are:
Latent-to-Pixel Conversion:
The decoder uses 3D transposed convolutional layers to upsample the latent representation back to the original video resolution.
Final Denoising Step:
Unlike traditional VAEs, the decoder in LTX-Video is also responsible for performing the final denoising step. This means it not only converts latents to pixels but also removes any remaining noise, producing a clean output directly in pixel space.
Novel Loss Functions:
The decoder is trained using novel loss functions that ensure high-quality reconstruction of fine details, even at high compression rates.

Shared Diffusion Objective
The shared diffusion objective is a novel approach that integrates the denoising process into the VAE decoder. This allows the decoder to perform both latent-to-pixel conversion and the final denoising step, producing clean outputs directly in pixel space.

Reconstruction GAN (rGAN)
The Reconstruction GAN (rGAN) is a novel adaptation of the traditional GAN framework, specifically designed for reconstruction tasks.

Multi-layer Noise Injection
Multi-layer Noise Injection is a technique inspired by StyleGAN, where noise is added to multiple layers of the VAE decoder during the generation process.
This noise introduces stochasticity (randomness) into the generation process, enabling the model to produce diverse and detailed outputs.

Uniform Log-Variance

Video DWT Loss
To ensure the reconstruction of high-frequency details, LTX-Video introduces a spatio-temporal Discrete Wavelet Transform (DWT) loss.
A. Implementation
The 3D DWT is applied to both the input and reconstructed videos, producing 8 wavelet coefficients.
The L1 distance between the wavelet coefficients of the input and reconstructed videos is used as the loss

Video Transformer
The Video Transformer in LTX-Video is a critical component responsible for modeling the spatiotemporal relationships in video data. It builds upon the Pixart-α architecture but introduces several key modifications to improve performance, including Rotary Positional Embeddings (RoPE) and Query-Key (QK) Normalization. Below, I will explain these components in detail, including the mathematical formulations and design choices.
Rotary Positional Embedding (RoPE)
What is RoPE?
Rotary Positional Embedding (RoPE) is a type of positional encoding that dynamically encodes the position of tokens in a sequence. Unlike traditional absolute positional embeddings, RoPE incorporates relative positional information in a more flexible and context-aware manner.
Why RoPE?
Video data involves varying sequence lengths (due to different resolutions, frame rates, and durations). RoPE is better suited for handling such variability compared to absolute positional embeddings.
RoPE allows the model to generalize better across different resolutions and frame rates, making it ideal for video generation tasks.


Query-Key (QK) Normalization
In transformer architectures, the attention mechanism computes the dot product between queries (Q) and keys (K) to determine the attention weights. However, when the values of QQ and KK are too large, the attention logits can become extremely large, leading to near-zero entropy in the attention weights. This reduces the model’s ability to focus on relevant tokens.
QK normalization stabilizes the attention computation by normalizing the queries and keys before the dot product. This ensures that the attention weights have higher entropy, improving the model’s ability to capture long-range dependencies.

Text Conditioning
Text conditioning ensures that the model accurately interprets and generates content based on textual input. LTX-Video uses a combination of pre-trained text encoders and cross-attention mechanisms to achieve robust text-to-video synthesis.
LTX-Video found that cross-attention works better than MM-DiT (Multi-Modal Diffusion Transformer), which processes text and image embeddings in parallel.
Cross-attention allows for more direct interaction between the text and video tokens, improving the model’s ability to generate content that aligns with the text prompt.
Image Conditioning
Image conditioning allows the model to generate videos starting from a given first frame, which can be either real or generated. This is useful for tasks like image-to-video generation.


Rectified-Flow Training
The training procedure in LTX-Video is based on Rectified Flow, which improves the efficiency and quality of the diffusion process.

Dataset Composition
The training dataset consists of publicly available data and licensed material, ensuring diversity and comprehensiveness.
The dataset is designed to enable the model to generate a wide variety of visual content.
Quality Control and Filtering
Aesthetic Model: A Siamese Network is trained to evaluate the aesthetic quality of videos and images. The model is trained on manually tagged image pairs to predict an aesthetic score.
Filtering: Samples with low aesthetic scores are filtered out, ensuring only visually appealing content is used for training.
Motion and Aspect Ratio Filtering: Videos with insignificant motion are removed, and black bars are cropped to standardize aspect ratios.
Fine-Tuning with Aesthetic Content
The most aesthetically pleasing content is selected for fine-tuning, improving the visual quality of the generated outputs.
Captioning and Metadata Enhancement
An automatic captioner is used to re-caption the entire training set, ensuring accurate and relevant text descriptions.
This improves the alignment between visual content and textual annotations, enhancing the model’s ability to generate content based on text prompts.
Experiments and Evaluation
Training: The model is trained using the ADAM-W optimizer and fine-tuned on high-aesthetic videos.
Evaluation: A human survey is conducted to compare LTX-Video with state-of-the-art models (Open-Sora Plan, CogVideoX 2B, PyramidFlow) on text-to-video and image-to-video tasks.
Survey Results: LTX-Video significantly outperforms other models in both tasks, with win rates of 85% for text-to-video and 91% for image-to-video.
Pairwise Comparisons: LTX-Video consistently wins against other models, as shown in the pairwise performance matrix