
EMO2 Paper Explained
[Daily Paper Review: 22-01-25] EMO2: End-Effector Guided Audio-Driven Avatar Video Generation

Audio-driven video generation seeks to create synchronized human animations (both facial expressions and body gestures) based on audio input. While prior research has advanced significantly in generating talking-head videos, replicating rich, natural, and audio-synchronized body gestures remains a major challenge.
Key Issues Identified:
Weak Correlation Between Audio and Full-Body Gestures: Audio signals are closely related to some body parts (like hands) but weakly correlate with others (like torso or leg movements). Prior works treat the body as a holistic system, diluting this audio-gesture correspondence.
Human Body Complexity: The human body operates as an articulated system with many degrees of freedom. Predicting synchronized, natural motion for co-speech videos becomes highly complex due to:
Variations in joint coupling.
The difficulty of mapping audio directly to the pixel or joint level.
Limitations of Current Methods: Most existing models predict body poses (e.g., skeleton or SMPL parameters) directly and convert them to video. These approaches:
Fail to reproduce intricate and natural co-speech gestures.
Lack generalization to diverse audio scenarios.
Struggle with creating vivid, expressive human motion.
The study introduces a two-stage framework inspired by the principles of robotic motion planning and inverse kinematics (IK):
Robots control their movement by prioritizing the "end-effector" (e.g., the gripper or hand). The end-effector's movement determines how the rest of the body adjusts, simplifying the motion planning process.
Analogously, human hands often act as the "end-effectors" in communication. Hand gestures are:
Strongly correlated with audio input (e.g., gesturing while speaking).
More direct representations of human intent compared to other body parts.
Hypothesis: If human hand gestures (end-effector) can be accurately modeled from audio, the rest of the body's motion (head, torso, facial expressions) can follow naturally by leveraging existing generative models.
Background: What Are Robotic Control Systems?
Robotic control systems, such as manipulators (robotic arms) or humanoid robots, are engineered to mimic human behaviors and motions. To perform tasks, these systems need to move their "joints" in a coordinated way. However, controlling each individual joint independently is very complex, especially when there are many joints, as in a human body.
End-Effector (EE): What Is It?
The end-effector (EE) is the "tool" or "endpoint" of a robot. For example:
A robotic arm's EE could be a gripper or a welding tool.
In the human analogy, your hands are the EEs.
Instead of controlling every joint in the robot, you focus on the EE. You determine where the EE should go (its position) and how it should be oriented (its posture). The robot then calculates how to move its joints to achieve the desired EE position and posture.
Degrees of Freedom (DoF): What Is It?
DoF refers to how many independent ways a system can move.
A hand in 3D space has 6-DoF:
Move left/right (x-axis)
Move forward/backward (y-axis)
Move up/down (z-axis)
Rotate around the x-axis (roll)
Rotate around the y-axis (pitch)
Rotate around the z-axis (yaw)
Simplifying Control: Why Focus on the EE?
Controlling each robot joint individually is complicated and computationally expensive. For instance, a robotic arm with 10 joints would require you to calculate how all 10 joints need to move for even the simplest task (like picking up an object).
Instead, robotic systems focus on controlling the EE. Using a method called Inverse Kinematics (IK):
You specify the desired EE position and posture.
The IK algorithm computes the required joint movements to achieve that EE position.
What Is Inverse Kinematics (IK)?
IK is like solving a puzzle where you need to figure out how to position multiple joints (arms, legs, etc.) so that the endpoint (EE) reaches a specific target.
For example:
Suppose you want to grab a cup on a table.
You know the cup’s location (target position).
IK computes how your shoulder, elbow, and wrist must move so your hand reaches the cup.
Challenges with IK in Robots and Humans
IK doesn’t always work perfectly because it involves solving complex mathematical equations. Some of the challenges include:
Singularities: These are points where the IK solution becomes unstable, causing awkward or jerky movements.
Multiple Solutions: For a given EE position, there may be many valid joint configurations. Choosing the most natural one is difficult.
To address these problems:
Robotic systems incorporate prior knowledge (predefined rules or constraints) to ensure that the computed movements look natural and efficient.
Connecting This to Human Motion
The paper draws a parallel between robotic systems and human motion:
In human motion, the hands (our EEs) are closely tied to our intentions.
For example, when we talk, our hand gestures often reflect what we’re saying.
Instead of trying to control every joint in the body (shoulders, elbows, wrists, etc.), the focus can be on generating natural hand movements. The rest of the body can then follow using principles similar to IK.
This is an important simplification because hand movements are strongly correlated with audio signals, while the motion of other joints may not be as directly tied to speech.
Motivation for the Approach
Traditional methods in audio-driven human motion generation attempt to predict the positions of all body joints or even generate the entire video directly. These approaches often fail to:
Capture complex body dynamics, as predicting the motion of many joints is very challenging.
Synchronize well with audio.
Inspired by robotics, the authors redefine the problem:
Focus on the hands (EEs): Generate natural hand gestures from audio signals.
Let the body follow: Use generative models to create the rest of the body’s movements and facial expressions, guided by the hand poses.
Pixel-Space IK and Generative Models
Generative models like diffusion models are used for generating videos frame by frame. These models:
Work directly in pixel space (the video frames).
Implicitly learn how human bodies move together (e.g., how the arms move with the shoulders).
The authors propose that instead of explicitly solving IK for all joints, the generative model can handle this task in pixel space. The hand gestures (produced in the first stage) serve as inputs to guide the model, ensuring:
Natural motion of the entire body.
Realistic synchronization of audio with gestures and lip movements.
This is referred to as "pixels prior IK"—the idea that pixel-generation models inherently incorporate the principles of IK while synthesizing realistic motio
Proposed Framework
The solution is split into two major stages to simplify the problem and improve generation quality:
Stage 1: Audio-to-Hand Pose Mapping
Why this stage? Hands act as the "end-effector," exhibiting the strongest correlation with audio. Mapping audio to hand gestures simplifies the problem space by focusing on the most informative body part.
Stage 2: Diffusion-Based Video Synthesis
Why diffusion? Diffusion models excel at generating high-quality, realistic videos by learning to reverse a noise-adding process. They offer:
Enhanced detail and smoothness in generated videos.
Better temporal consistency for continuous motion.
Key Components in Stage 1

The architecture revolves around a motion diffusion transformer (DiT), which uses noisy motion latents and cross-attention with audio embeddings to generate coherent hand gestures. The process includes:
Preprocessing Inputs:
Noisy Motion Sequence: Input sequences (representing motion data) are perturbed with Gaussian noise for training, following the principles of the Denoising Diffusion Probabilistic Model (DDPM).
Hand Motion Mask: Used to account for frames where hand annotations (MANO coefficients) are missing or inaccurate.
Offset Embedding: Captures relative body pose differences, disentangling hand motion from overall posture.
Audio Encoding:
Audio features are extracted using Wav2Vec. This produces high-quality audio embeddings that align with motion.
Time Embedding and Auxiliary Signals:
Timestep embeddings are injected into the DiT backbone using AdaLN-single normalization.
Style and speed embeddings allow for additional control:
Style Embeddings: Encoded signals for styles like singing or gesturing.
Speed Embeddings: Encoded using the variance of hand translation, representing the motion amplitude.
Cross-Attention Mechanism:
Audio Embedding → Noisy Motion Latents: Multi-head attention ensures audio and motion are synchronized.
Transformer-based Architecture:
The motion generator uses DiT blocks with:
Self-Attention: Operates on noisy motion latents.
Cross-Attention: Aligns motion latents with audio embeddings.
Output Co-Speech Gestures:
The generated hand motions serve as control signals for Stage 2, representing co-speech gestures.
Concatenation for Temporal Smoothness:
The model concatenates the last frame of the previous sequence to the current noisy motion sequence, ensuring temporal consistency.


Key Components of the Stage 2 Architecture
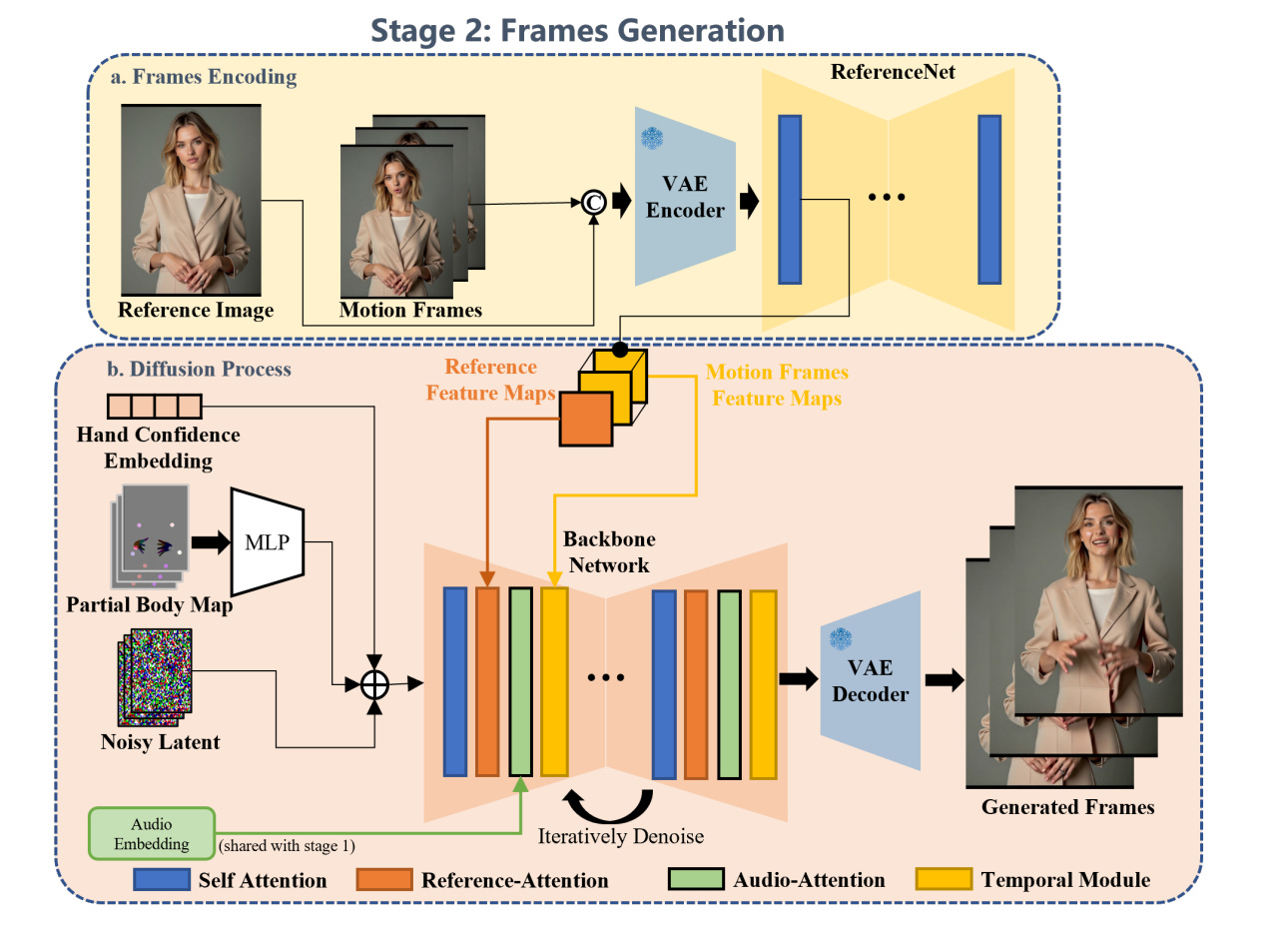
1. Denoising Process
Backbone Network:
The backbone is a 2D-UNet augmented with temporal modules inspired by AnimateDiff.
The noisy latent frames are iteratively denoised to reconstruct the target video sequence.
Integration of temporal modules ensures smooth transitions and dynamic consistency between frames.
Latent Input and MANO Maps:
Latent inputs include noisy frames, partial body maps, and MANO maps from Stage 1.
These are concatenated channel-wise and modulated with latent features for detailed motion control.



Implementation Details
Hand Motion Generation:
Backbone: 24 DiT blocks with a hidden size of 512.
Hand Model: MANO with 48 joint rotation values (axis-angle), converted to 64 quaternion parameters + 3 translation values, totaling 134 parameters for both hands.
Sequence Length: Padded to 300 frames, with a 12-frame context for smooth transitions.
Training:
GPU: A100.
Batch Size: 8.
Steps: 400k.
Dataset: MOSEI, AVSPEECH, and 275 hours of internet-collected videos.
Video Generation Model:
Training Stages:
Stage 1 (Image Training):
Input: 2 cropped frames (704 × 512) as reference and target.
Components: ReferenceNet, motion guidance layer, and backbone modules.
Stage 2 (Audio-Video Training):
Input: 24 frames (704 × 512) with 12 motion frames.
Components: Temporal modules, audio attention layers, additional modules (ReferenceNet frozen).
Training:
GPUs: 4 A100.
Batch Sizes: 32 (image stage), 4 (audio-video stage).
Steps: 100k per stage.
Learning Rate: 1 × 10⁻⁵.
Result
Hand Motion Metrics
Diversity (DIV):
What it measures: How varied and expressive the generated hand movements are across different sequences.
Significance: High diversity indicates natural and vivid motion, avoiding repetitive or monotonous gestures.
Beat Alignment (BA):
What it measures: How well the hand movements are synchronized with the rhythm or beats of the audio.
Significance: High alignment reflects natural co-articulation between audio and gestures.
PCK (Percentage of Correct Keypoints):
What it measures: The percentage of generated hand poses that are close to the ground truth (real-world data).
Significance: Higher PCK means the generated motion is more realistic and closer to observed human motion.
FGD (Frechet Gesture Distance):
What it measures: The statistical distance between the distribution of generated hand gestures and the ground truth gestures.
Significance: A lower FGD indicates that the generated motions closely mimic real-world hand movement distributions.
Video Generation Metrics
Image Quality:
FID (Frechet Inception Distance):
What it measures: The perceptual similarity between generated images and real images using deep feature embeddings.
Significance: Lower FID scores indicate higher-quality generated images that are closer to real ones.
SSIM (Structural Similarity Index Measure):
What it measures: The structural similarity between generated and reference images.
Significance: Higher SSIM values indicate better preservation of structural details.
PSNR (Peak Signal-to-Noise Ratio):
What it measures: The fidelity of pixel values between generated and reference images.
Significance: Higher PSNR values indicate better pixel-level quality and less distortion.
Video Coherence (FVD):
Frechet Video Distance:
What it measures: The coherence and smoothness of frame transitions in a generated video.
Significance: A lower FVD indicates smoother and more natural-looking motion over time.
Identity Consistency (CSIM):
What it measures: The cosine similarity between facial features in the reference image and the generated video frames.
Significance: High CSIM values ensure that the generated avatar maintains the identity of the reference image.
Hand Movement Quality:
HKC (Hand Keypoint Confidence):
What it measures: The quality and accuracy of hand keypoint representations in the generated frames.
Significance: Higher HKC scores indicate sharper and more precise hand poses.
HKV (Hand Keypoint Variance):
What it measures: The diversity of hand keypoint movements in the generated frames.
Significance: Higher HKV values represent more varied and dynamic hand movements.
Facial Expression Quality (EFID):
What it measures: The divergence in facial expressions between the generated videos and the ground truth dataset.
Significance: Lower EFID scores indicate that the generated facial expressions are more natural and closely aligned with the ground truth.
Synchronization (Sync-C):
What it measures: The alignment and synchronization between lip movements and audio signals.
Significance: Higher Sync-C values indicate better lip-sync, making the video more realistic and believable.
Hand Motion Generation Comparisons
Datasets: Compared using the Talkshow dataset.
Metrics:
Diversity (DIV): Superior results compared to SMPL-based methods.
Beat Alignment (BA): Outperformed SMPL-based methods.
PCK and FGD: Lower scores due to more flexible hand movements, as MANO allows greater diversity than SMPL forward kinematics.
Key Observations:
MANO-based method produces vivid, expressive, and diverse hand motions.
SMPL-based methods are restricted and tend to generate monotonous motions.
Video Generation Comparisons
Dataset: EMTD for upper-body animation.
Metrics:
Image Quality: Assessed using FID, SSIM, and PSNR.
Video Coherence: Evaluated using FVD.
Identity Consistency: Measured with CSIM.
Hand Movement Quality:
HKC: Measures hand representation quality.
HKV: Indicates motion diversity.
Facial Expression Quality: Evaluated using EFID.
Synchronization: Lip-audio sync measured with Sync-C.
Results:
Higher HKV indicates superior motion diversity compared to baselines.
Lower EFID and better Sync-C highlight expressive and synchronized facial animations.
Comparisons with CyberHost and Vlogger demos show better motion diversity and image quality.